Presearch gpt-3 AI
Presearch GPT-3 AI ➡️ Mesterséges Intelligencia
Miért is hozom szóba a Presearch GPT-3 AI lehetőséget❓ Mostanság a GPT-3 OpenAI -tól zeng az egész média❗
✅ Arról lehet hallani folyamatosan, hogy például az OpenAI és a Microsoft a saját Bing nevű keresőgépén keresztül dolgoznak a ChatGPT-n.
Mivel a ChatGPT-vel és a 🔗 mesterséges intelligenciával (AI) kapcsolatos hírek nagy hatással vannak az olyan Big Tech keresőmotorokra is, mint amilyen a Google, érdekes lehet a lehetőségeket megnézni.
🤔 Az a keresőgép amiről igen részletesen én már írtam Nektek, a 🔗 Presearch, miképpen kívánja kiaknázni a mesterséges intelligenciában rejlő lehetőségeket❓👇
Úgy gondolom mindenképpen megér egy témát. Hiszen korunk jelenleg még domináns keresőgép tulajdonosa válságstábot is létre hozott annak érdekében, hogy ne maradjanak le. Még az alapítókat is visszahívták 😉
✅ Pedig a jövőben nem is a Bing lesz az ellenlábasa amitől annyira retteg. Mert az emberek számára az adatvédelem és a privát szférájuk egyre fontosabb lesz.
📣 Így a Presearch kultusza csak fejlődni fog❗
Presearch GPT-3 AI alapú kereső

Ezt a blogbejegyzést azért készítettem, hogy feltárjam magyar nyelven, azokat a lehetőségeket, hogyan is használja a Presearch az AI-t. Most és a jövőben.
A Presearch jelenleg az OpenAI GPT-3-at használja a mesterséges intelligencia-keresési élmény prototípusának működtetésére. Ezt először zárt béta-verzióban 2022 decemberében vezette be. A keresőmotorok úttörők a mesterséges intelligencia terén, hiszen évek óta gépi tanulási (ML) algoritmusokra épülnek.
Nagy mennyiségű adatok
💭 Miből is tevődik össze a nagy mennyiségű keresendő adat❓
- a szándékukat jelző felhasználóktól érkező lekérdezések,
- valamint a folyamatos felhasználói interakciókból. Kattintások, lapozás, görgetés, származó valós idejű visszajelzések kombinációjából.
✅ Egy AI-alapú keresőmotor tehát az a képesség, hogy folyamatosan tanuljunk és fejlődjünk az új adatokból és interakciókból.
ChatGPT

Az elmúlt hónapok eseményei alapján mondhatom, hogy drámaian megnőtt az emberek érdeklődése a mesterséges intelligencia erejének megértése iránt. Főként az OpenAI által elindított ChatGPT interfésznek köszönhetően. Az interfészre előzetesen lehetett / lehet regisztrálni és kommunikációt folytatni a mesterséges intelligenciával, pontosabban nyelvi modellel.
A ChatGPT már a jelenlegi működésének lenyűgöző szakaszában, a mesterséges intelligencia gyorsan fejlődő jövőbeli lehetőségeinek tömeges megismeréséhez vezetett. Novemberi bevezetése amolyan „iPhone-pillanat” volt az AI-technológia számára, amely lenyűgöző csevegési élményt biztosított.
Annyira intelligens és emberszerű, hogy a tesztelésre 5 nap alatt, több mint 1 millió felhasználó jelentkezett.
Mi is az az LLM❓
Ez a ChatGPT több évnyi nyílt innovációt, tudást csomagol be az LLM – Large Language Models keresztül. Különféle vállalatok és kutatók lettek bevonva, természetesen az OpenAI mellett. Vélhetően megnyitja az utat egy jelentős innovációs hullám előtt a mesterséges intelligencia területén a következő néhány évben.
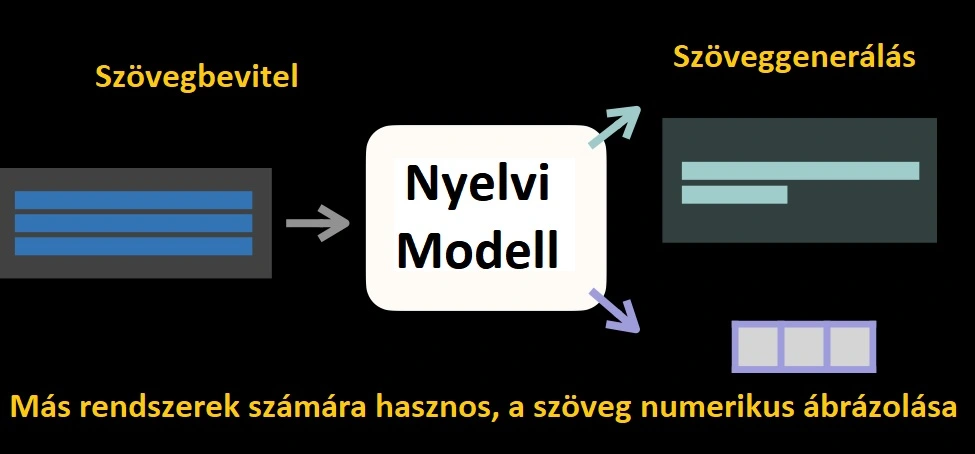
✅ A Nagy Nyelvi Modellek (LLM) olyan mesterséges intelligencia eszközök, amelyek képesek szövegeket olvasni, összefoglalni és lefordítani, valamint megjósolni a jövőbeli szavakat egy mondatban. Ez teszi lehetővé, hogy az emberek beszéd- és írásmódjához hasonló mondatokat generáljanak.
Csakúgy érdekességként,
💭vajon mi a chatGPT véleménye saját maga és a GPT-3 közötti különbségről❓
ℹ️ Nos, az alábbiakat mondta el, amit angolról fordítok át magyarra, de mivel a saját véleménye volt, így Isten mentsen engem, hogy plagizáljak, ezért ⬇️ idézettel jelölöm 😄
📜 Különbségekről, ahogy gigászi adatbázisában elérhető adatokból, adekvát válaszát generálta 👇
„ A ChatGPT és a GPT-3 az OpenAI által kiképzett Nagy Nyelvi Modellek, de van néhány lényeges különbség. A GPT-3 vagy a Generative Pretrained Transformer 3 az OpenAI GPT nyelvi modelljének harmadik generációja, ez az egyik legerősebb jelenleg elérhető nyelvi modell. A természetes nyelvi feldolgozási feladatok széles skálájára finomhangolható, beleértve a nyelvi fordítást, a szövegösszegzést és a kérdések megválaszolását.
A ChatGPT viszont a GPT-3 modell egyik változata, amelyet kifejezetten chatbot alkalmazásokhoz terveztek. A párbeszédes szövegek nagy adatkészletére képezték ki, így képes olyan válaszokat generálni, amelyek alkalmasabbak chatbot-kontextusban való használatra. A ChatGPT arra is képes, hogy megfelelő kontextus-specifikus válaszokat illesszen be a beszélgetésekbe, így hatékonyabban tartja fenn a koherens beszélgetést.”
Fontos kihangsúlyozni, válaszát a cikkem írásában időpontjában adta, ahogy befejezte, az idő előrehaladtával már nyilván érvényét veszítheti❗
„ A teljesítmény szempontjából a ChatGPT nem olyan erős, mint a GPT-3, de chatbot-alkalmazásokhoz jobban megfelel. Általában gyorsabb és hatékonyabb, mint a GPT-3, ami jobb választássá teszi valós idejű chatbot rendszerekben való használatra. Összességében a ChatGPT és a GPT-3 egyaránt erőteljes nyelvi modell, de különböző célokra készültek, és eltérő erősségekkel és gyengeségekkel rendelkeznek.”
A Presearch GPT-3 AI-alapú keresés fejlesztése a Presearch technológiai igazgatója kezében összpontosul
Trey Grainger az 📖 🔗 „AI-Powered Search” című könyv szerzője, s ez például arról szól, hogyan lehet a mesterséges intelligenciát a keresési tapasztalatok kontextusában megvalósítani.
Trey éveket töltött mérnöki vonalon mint alelnök, majd algoritmus fejlesztési területen vezérigazgatóként egy mesterséges intelligencia-alapú keresőmotort fejlesztő cégnél. Kifejlesztette a világ több száz vezető vállalatát biztosító AI-képességeken alapuló keresési funkciót. Számos könyvet, cikket és kutatási anyagot is publikált a keresés és a mesterséges intelligencia relevanciájában.
Presearch részről tehát elmondható, hogy az AI-alapú keresési funkció fejlesztése, hozzáértő, tapasztalt kezekben van.
A cikk által, ha tovább olvasod, bepillantást nyerhetsz, hogy az AI milyen kulcsszerepet fog játszani a Presearch decentralizált keresőgép működése során. A Presearch hamarosan elkészíti fehérkönyvének (whitepaper) módosított változatát is, amelyben részletesen fogja bemutatni az AI projektet.
Miért számít a fentiekben ismertetett LLM annyira a Presearch számára❓
Ahogy említettem a Presearch jelenleg az OpenAI GPT-3-at használja. Az 🔗 OpenAI 2015-ös alapítása óta dolgozik az AI-n, de a nagy nyelvi modellekre (LLM) összpontosított a Google által közzétett híres 🔗 „Attention is all you need” című cikk megjelenése után.
💡 A tanulmány új architektúrát javasolt a nyelvi modellekhez, a Transformer-t, amely figyelemmechanizmusokat használ a több szóra vagy mondatra kiterjedő nyelvi minták azonosítására.
A transzformátorokat nagy adathalmazokon (leggyakrabban szövegen) mély tanulással képezik, hogy megtanulják mind az adatkészletekben jelenlévő nyelvi, mind pedig fogalmi kapcsolatokat.
A transzformátorokról
Felépítésileg a transzformátorok általában egy
kódolóból
amely képes a szöveget (vagy más bemeneteket, például képeket vagy hangot) numerikus kontextusvektorokká képezni, valamint
dekódolóból
állnak, ami átveszi ezeket a kontextusvektorokat, és visszaképezi őket szöveggé. A kontextusvektorokat vagy beágyazásokat úgy tekintheti, mint a bemenet jelentésének numerikus reprezentációját, amelyet a nyelvi modell megért.
Tehát a „kiment sétálni az utcán” szöveget lehet kódolni egy beágyazásba, mint például [0,12, 9,51, 6,42, … 0,32], és ugyanez a beágyazás dekódolható hasonló szöveggé, például „a lány sétált le, fel az utcán”.
Ha a szöveg, amelyre a modellt betanították, többnyelvű lenne, akkor egy másik nyelven azonos jelentésű szöveg szintén nagyon hasonló beágyazáshoz lenne leképezve, mivel ugyanazt a jelentést hordozza.
ℹ️ A transzformátorok lényegében megtanulhatják a szavak és kifejezések jelentését a különböző kontextusokban, valamint a szavak és kifejezések kombinálását meghatározó nyelvi konstrukciókat.
✅ Ez az architektúra számos feladatban felülmúlta a korábbi modelleket, beleértve a gépi fordítást, a nyelvi modellezést és a kérdések megválaszolását.
A Transformer architektúrájáról
Az önfigyelem elvén alapul, amely lehetővé teszi a modell számára, hogy a bemenet különböző részeit egyidejűleg vegye figyelembe. Ez lehetővé teszi a modell számára, hogy rögzítse a hosszú távú függőségeket a bemenetben, ami elengedhetetlen a potenciálisan nagy kontextusban használt nyelvben található összetett kapcsolatok megértéséhez.
👏 A Transformer egy „többfejes” figyelemmechanizmust is használ, amely lehetővé teszi a modell számára, hogy a bemenet különböző részeit párhuzamosan kezelje. Ennek köszönhetően a modell, bonyolultabb kapcsolatokat tud rögzíteni a szavak között.
2019-ben a Google-t a BERT hajtotta
Miután bemutatta a Transformers-t a világnak, a Google 2019-től a Transformer-alapú BERT nyelvi modelljével továbbfejlesztette keresőjét, és sok keresőmotor folytatta az ilyen típusú nyelvi modellek fejlesztését és kihasználását a lekérdezés-értelmezési és rangsorolási rétegben.
Azóta a Transformer architektúra lehetővé tette nagyobb nyelvi modellek, mint amilyen például a GPT-3, vagy Flan t5 fejlesztését. Ezek képesek megragadni a szavak közötti összetettebb kapcsolatokat, és meggyőző válaszokat generálni kérdésekre és utasításokra, majd megjósolja a helyes választ a bemeneti kontextus alapján.
Ez a lényege annak, ami a ChatGPT mögött áll, ami lehetővé tette az OpenAI számára, hogy olyan terméket hozzon létre, amely magával ragadta a világot❗
A Presearch az AI-t, azaz mesterséges intelligenciát egy teljesen decentralizált indexen keresztül használja ki
Nem titok, hogy a Presearch hosszú távú célja egy teljesen decentralizált kereső felépítése. Ennek egyik központi eleme a világ információinak decentralizált indexe.
A mesterséges intelligencia technológiája nemcsak a fogyasztói élményként fog az index menedzselésének felső szintjén helyezkedni, hanem aktívan felhasználják az adatok particionálására és indexelésére, megfelelő tárolására és replikálására, valamint a lekérdezések megfelelő indexpartíciókra irányítására.
Míg a Presearch jelenleg az OpenAI-t használja mesterséges intelligencia élmények fokozására,
✅ ezt végül olyan nyílt forráskód alapú modellek váltják fel,
amelyeket a világ legjobb mérnökei segíthetnek felépíteni, betanítani és integrálni a Presearch részeként.
A Presearch jövőképe a mesterséges intelligencia területén
Az OpenAI modelljei nagy hozzáadott értéket jelentettek a Presearch számára, lehetővé téve, hogy egy nagyon robusztus mesterséges intelligencia tapasztalattal, gyorsan piacra kerüljön a cég, de a Presearch hálózatot végső soron, a saját mesterséges intelligencia alapú technológiája fogja működtetni, kihasználva a nyílt forráskódú modelleket, amelyek mélyen integrálódnak a decentralizált indexbe.
A Presearch alapvetően más megközelítést alkalmaz a mesterséges intelligencia technológiájának kiépítéséhez, decentralizált és nyitott, az elosztott képzés erejét kihasználva. Ennek azért az adatvédelem és személyiségi jogok területén óriási jelentősége van. S nem csinálok belőle titkot, de mióta publikáltam a cikket erről a keresőgépről, azóta pontosan ezért az ismérvéért használom, hanyagolva a többit. 😉
Az elosztott képzésről, ha már említettem
Az elosztott képzés az AI modellek több gépen történő egyidejű betanításának módszere. Ez gyorsabb betanítási időt tesz lehetővé egy decentralizált architektúrában, ami pontosabb modellekhez vezet, amelyek jobban megértik a felhasználói lekérdezések körülményeit, és végső soron relevánsabb keresési eredményeket biztosítanak.
Globálisan decentralizált index
A Presearch egy globálisan decentralizált indexet is igyekszik kihasználni, amelybe ezeknek a képzett AI-modelleknek a beágyazásait mélyen integrálták.
Ez gyorsabb és pontosabb keresést tesz lehetővé azáltal, hogy mélyebben megérti a felhasználói lekérdezéseket, majd korlátozza az adott keresés végrehajtásához szükséges csomópontok számát.
A mesterséges intelligencia alapú beágyazásokon nyugvó, globálisan decentralizált index állomány particionálásával:
- a Presearch optimalizálhatja a lekérdezések sebességét
- és maximalizálhatja a hálózati erőforrásokat, miközben a legrelevánsabb eredményeket is biztosítja.
Elosztott képzés és globálisan decentralizált index kombinációja :
Lehetővé teszi a Presearch számára, hogy valóban decentralizált keresőmotort biztosítson, amelyet a legjobb nyílt forráskódú közösség által épített mesterséges intelligencia modellek hajtanak.
A Nagy Nyelvi Modellek (LLM), bár jelenleg nagyon népszerűek, messze nem az egyedüli AI-képességek, amelyek általánosak a keresőmotorokban, de mint tudjuk a mainstream mindig megteszi a hatását 😊
A Presearch az elosztott képzést az alábbira használja:
- a gépi úton tanult rangsoroláshoz (más néven a rangsorolás megtanulásához),
- a jeleket növelő modellekhez,
- a tudásgráf generálásához
✅ és sok más technikához a jobb rangsorolási tényezők megismeréséhez és létrehozásához.
A Nagy Nyelvi Modellek (LLM) azonban kritikus szerepet fognak játszani az eredmények átgondolt és hasznos értelmezésében és összefoglalásában.
Míg a Google válságstábot állított fel, addig a Presearch stratégiája ⬇️
Alapvetően más megközelítést alkalmaz, mint az OpenAI és más keresőmotorok, mivel a nyíltforráskódú koncepciót követi, valamint az együttműködésre és a decentralizációra összpontosít.
Amit a 🔗 Bitcoin tett a digitális valutáért, azt a Presearch megteszi a világ információihoz való hozzáférésért❗
Ha szeretnél részt venni a projektben, decentralizált csomópontot működtetni, segíteni az építésben, vagy egyszerűen csak szeretnél többet megtudni, örömmel üdvözölnek Téged is a közösség tagjaként!
Milyen hatást gyakorolhat mindez a jövőre, az Online Marketing aspektusából❓
Úgy vélem az online marketing számára nagyon is pozitív hatást gyakorol.
Ez már a Google keresőgépen is meglátszik, hiszen ha átnézzük a Google keresőalgoritmusainak fejlődését, akkor a Mesterséges Intelligencia egyre nagyobb teret, jelentőséget kap. S azt kell, hogy mondjam a régi idők viszonylatában, hogy a 🔗 SEO és 🔗 keresőmarketing tevékenységet végzőknek is sokkal kényelmesebb, hiszen elmondhatjuk,
✅ hogy tényleg tartalomban a lényeg. 😉
A keresés során az algoritmus értelmezőképessége sokat segíthet❗
A keresőgépek használatakor, amelyek között jómagam, a Presearch-nek jósolom a legnagyobb szeletet, a lényeg már nem a puszta matematika lesz.
Hanem adatok, előértelmezéssel történő megszűrése, s mint tudjuk, az értelmezett adat, az információ.
Tehát ha a keresőgép értelemmel tudja átlátni a Te weboldalad, akkor sokkal könnyebben fogja tudni releváns javaslatként azt a felhasználójának felkínálni. Ez pedig elősegítheti a konverziós folyamatokat. Hiába, eljárt már afelett az idő, hogy hosszú éjszakákba nyúlva, egy kis kávé mellett, potenciális linkcsere partnerek után kutattunk 😅
🤔 Itt az értelem, akkor most intelligencia❓
Őszintén megmondom nekem sokkal szimpatikusabbak a tartalomfejlesztés szemszögéből a modernebb keresőalgoritmusok, amelyek értelemmel próbálnak az adatbázisnak nekiugrani.
💭 A kérdés csak az, mivé fejlődhet❓
Szerencsére egyelőre a Mesterséges Intelligencia témában öntudatra ébredésről nem beszélhetünk, bár lehet nem is a megfelelő személy vagyok, hogy ezt kijelentsem, hiszen igazából az öntudatra ébredés folyamatát a mai napig nem tudjuk szakmailag levezetni.
Amikor cikkemben értelmezést, előértelmezést írtam, annak semmi köze az intelligenciához❗
A jelenség csupán a különböző GPT modellek fejlesztésének sajátosságai, ahol pont az erőforrások kímélése az egyik cél. A nagy adatbázisok feldolgozására szolgáló modellek lényege, ahol az adatok mint szövegek, tokenizálva jelennek meg, a cél pedig a gigantikus adatbázison belüli keresőfunkció felgyorsítása. A GPT-3 modell igen nagy előrelépés volt.
📣 Ha megosztanád írásom ⬇️
A világ globális működését feltérképező, s annak összefüggéseit megérteni óhajtó generalista vagyok. Célom nem más, mint az ismeretterjesztés.