
Ollama alternatívák
Ollama alternatívák 2026-ban avagy a lokális nyelvi modellek új korszaka és a hardverigények brutális valóságáról 👇
A lokálisan futtatott nagy nyelvi modellek (LLM-ek) 2026-ra kiléptek a geek-játék státuszból, és sok fejlesztőnél valódi infrastruktúrává váltak, ezért vélem, az Ollama alternatívák is érdekes téma lehet.
Ma már nem csak arról szól a történet, hogy „lehúzok egy modellt és elindítom”, hanem arról, hogy multimodális, agentikus, OpenAI-kompatibilis rendszereket építünk, amelyek egyszerre szolgálnak ki több
felhasználót, s közben persze zabálják a VRAM-ot, az áramot és az SSD-t.
🤔 Miért keresnek egyre többen Ollama alternatívák után❓
Az Ollama továbbra is remek belépőszint: egy parancs a modell letöltéséhez, egy másik a chat indításához,
és máris lehet kísérletezni.
A gond ott kezdődik, amikor a hobbiprojektből valódi alkalmazás lesz:
- több felhasználó,
- párhuzamos kérések,
- hosszú kontextus,
- multimodális input,
- agentikus eszköz-hívások.
A modern helyi LLM-stack már nem egyetlen binárisról szól, hanem külön inference motorokról,
desktop platformokról, API-szerverekről és orchestratorokról.
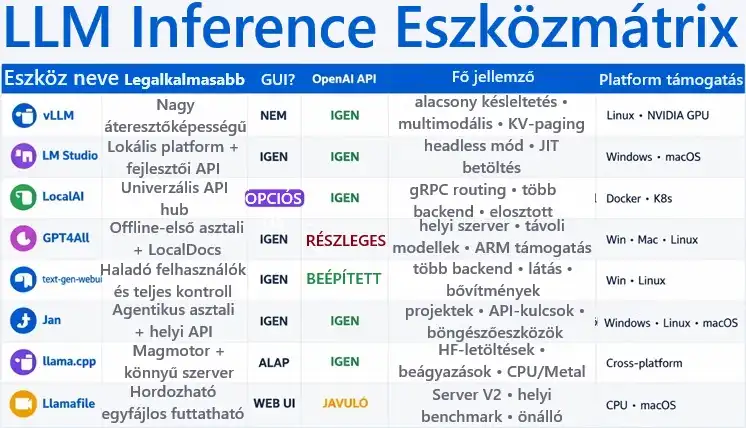
💡 A fejlesztők olyan Ollama alternatívák után néznek, amelyek:
- Magas áteresztőképességet adnak (continuous batching, fejlett scheduler, KV-cache optimalizáció).
- OpenAI-kompatibilis API-t kínálnak (chat, completions, embeddings, audio, vision, tool calling).
- Multimodális munkafolyamatokat támogatnak (szöveg, kép, audio, video, RAG, agentek).
- Agentikus képességeket hoznak (MCP, tool-hívás, böngésző-automatizáció, workflow-orchestration).
- Komoly testreszabhatóságot biztosítanak (kvantizáció, backend-választás, finomhangolás, template-ek).
A másik, kevésbé romantikus oldal a hardver. A 2026-os csúcsmodellek – különösen a 70B körüli, illetve a Mixture-of-Experts (MoE) architektúrák – már FP4 vagy hasonló kvantizáció mellett is 48–64 GB VRAM környékén érzik magukat igazán jól. A multimodális, hosszú kontextusú, több felhasználós terhelés pedig könnyen felviszi az igényt 96–128 GB VRAM szintre, több GPU-ra osztva.
✅ Ehhez jön:
- Magas GPU-ár (főleg a Blackwell generáció környékén).
- Jelentős áramfogyasztás (24/7 futó inference szervereknél ez már rezsiszintű tétel).
- SSD-igény (egy 70B modell több tucat gigabájt, több modellnél ez száz gigákban mérhető).
- Hűtés és zaj (a „kis otthoni AI-szerver” gyakran inkább mini gépterem).
Mindez együtt eredményezi, hogy az Ollama alternatívák világa ma már nem csak szoftveres döntés, hanem nagyon is kemény hardver- és költségkérdés. A következő fejezetben megnézzük, melyik eszköz melyik problémára ad értelmes választ.
Érdekes Ollama alternatívák 2026-ban
De persze, hogy friss, naprakész szakmai áttekintés, olyat nem mernék állítani. Részemről ez nem szakmai igénytelenség, pusztán a mesterséges intelligencia marketing címkébe burkolt nagy nyelvi modellek világa igen innovatív terep, ahol rendszeresen jönnek elő az új dolgok.
A 2026-os ökoszisztémát érdemes három nagy kategóriára bontani:
- Production engine-ek: vLLM, TensorRT-LLM, SGLang 2.0. Ezek a nagy terhelésre optimalizált motorok.
- Desktop platformok: LM Studio, Jan, GPT4All. Fejlesztőknek és haladó felhasználóknak, GUI-val és lokális API-val.
- Könnyű, hordozható runtime-ok: llama.cpp, Llamafile. Ha a hordozhatóság és a minimális függőség a lényeg.
Az alábbiakban álljon itt egy mustra a legfontosabb Ollama alternatívák listájáról, és megnézem, melyik milyen felhasználási esetre lehet ideális, milyen kompromisszumokkal jár, és milyen hardverrel érdemes számolni.
vLLM 1.2 – A teljesítménykirály (PagedAttention 2.0, multimodalitás, enterprise API)
A vLLM a 2026-os évre gyakorlatilag szabvánnyá vált, ha nagy áteresztőképességű, GPU-alapú inference-ről
beszélünk. A V1-es architektúra köré épülő 1.2-es verzió tovább finomította a PagedAttention megoldást,
amely hatékonyan kezeli a KV-cache-t sok párhuzamos kérés mellett. A continuous batching, a fejlett scheduler és a háttérben futó optimalizációk miatt a vLLM ideális választás olyan szolgáltatásokhoz, ahol
százával vagy ezrével érkeznek a kérések.
A vLLM OpenAI-kompatibilis API-t kínál: chat, completions, embeddings, audio-transcription,
rerank-endpointok, sőt multimodális pipeline-ok is elérhetők. A vLLM-Omni irányából érkező fejlesztések
lehetővé teszik, hogy szöveg, kép, audio és akár videó is ugyanazon infrastruktúrán fusson át.
A vállalati nézőpont szerint sajnos a hátránya nemcsak a hardverkörnyezet. Elsősorban Linux + NVIDIA környezetre optimalizált. Sok cég pedig még mindig idegenkedik a GNU/Linux világától, pedig szerintem az egyik legjobb és leghatékonyabb az operációs rendszerek között. Szóval igazán akkor mutatja meg az erejét,
ha komoly GPU-flottát kap maga alá. A vállalatok által vetített hardverigény hátránnyal már én magam is egyet tudok érteni.
Ha egyetlen gépen, egyetlen GPU-val szeretnél kísérletezni, vannak egyszerűbb Ollama alternatívák is, de ha production API-t építesz, vLLM az egyik legkomolyabb jelölt.
TensorRT-LLM 2026 : Gyors NVIDIA-optimalizált motor (FP4, QMoE, Blackwell)
A TensorRT-LLM az NVIDIA saját, mélyen optimalizált inference stackje, amely kifejezetten az aktuális
GPU-generációkra (Hopper, Blackwell stb.) van kihegyezve. A 2026-os lehetőségek szerint FP4, különféle
mixed-precision formátumok és MoE-specifikus kvantizáció (QMoE) is támogatott, így a modellek
jelentősen kisebb VRAM-lábnyom mellett is magas átviteli teljesítményt tudnak hozni.
A valóságban ez azt jelenti, hogy ugyanazon a kártyán (például egy RTX 5090-en) a TensorRT-LLM
gyakran érezhetően gyorsabb, mint a generikusabb motorok, viszont a setup bonyolultabb:
- modelleket kell konvertálni,
- buildelni, finomhangolni.
Ez tipikusan azoknak a csapatoknak való, akik dedikált ML/infra erőforrásokkal dolgoznak, és a plusz 30–70% teljesítményért hajlandók beletenni az extra munkát. Ha a célod egy „lokális OpenAI” jellegű szolgáltatás, és a költség per token kritikus, a TensorRT-LLM az egyik legkomolyabb, bár technikailag legnehezebb Ollama alternatívák közé tartozik.
SGLang 2.0 : strukturált generálás és programozható LLM-munkafolyamatok
Az SGLang 2.0 nem egyszerűen egy inference motor, hanem egy olyan runtime, amely az LLM-hívásokat
programként kezeli. A fókusz a strukturált kimeneteken (JSON, grammatikus output), a több lépéses
érvelési munkafolyamatokon és a KV-cache agresszív újrahasznosításán van. A háttérben gyakran vLLM-et
használ, de a fölé épített programozási modell miatt egészen más szintű kontrollt ad.
Olyan rendszerekhez ideális, ahol:
- szigorúan valid JSON-t vagy más formális struktúrát vársz,
- agentikus, több lépéses folyamatokat futtatsz,
- ugyanazt a kontextust sok hívás között újrahasznosítod.
Ha a célod nem csak egy chat-endpoint, hanem egy komplex, programozható LLM-réteg, az SGLang 2.0
az egyik legérdekesebb irány a 2026-os Ollama alternatívák mezőnyében.
LM Studio 0.4.x : A fejlesztői AI-platform (GPU-sharing, RAG 2.0, multimodalitás)
Az LM Studio az elmúlt években látványosan kinőtte a „szép GUI-s chatapp” kategóriát, és valódi fejlesztői platformmá vált. A 0.4.x verziókban megjelent a GPU-sharing, a fejlettebb RAG-pipeline, a multimodális modellek támogatása, és a headless „Local LLM Service” mód, amely lehetővé teszi, hogy a GUI bezárása után is fusson a lokális API-szerver.
Az LM Studio erősségei:
- Polírozott felület – modellek böngészése, letöltése, verziók kezelése.
- OpenAI-kompatibilis API – chat, completions, embeddings, responses endpointok.
- Beépített RAG – dokumentumfeltöltés, hosszú kontextus kezelése, lokális tudásbázis.
- Multiplatform – Windows, macOS, Linux.
Ha fejlesztőként szeretnél egy olyan eszközt, amivel egyszerre tudsz kísérletezni, demózni
és lokális API-t adni az alkalmazásodnak, az LM Studio az egyik legkényelmesebb Ollama alternatívák közé tartozik – különösen akkor, ha nem akarsz azonnal Dockerrel és Kubernetes-szel zsonglőrködni.
Jan 0.8.x : Agentikus desktop, MCP Marketplace, sandboxed tool execution
A Jan fókusza a kezdetektől az volt, hogy a helyi LLM-et összekösse a gépeddel és az eszközeiddel:
fájlokkal, böngészővel, workflow-kkal. A 0.8.x verziókban ez kiteljesedett: megjelentek a
projektek, az MCP Marketplace, a sandboxolt tool-végrehajtás és a komolyabb biztonsági beállítások
(API-kulcs, trusted hosts, hálózati kötés).
A Jan ideális választás, ha:
- agentikus, eszközhasználó AI-t szeretnél a desktopodra,
- lokális modelleket és felhős szolgáltatókat is kombinálnál,
- fontos a GUI, de kell egy biztonságos, lokális API-szerver is.
A Ollama alternatívák közül a Jan az, amelyik a leginkább „AI-automatizációs rétegként”
fogható fel a gépeden: nem csak válaszol, hanem cselekszik is – persze annyira, amennyire engeded.
GPT4All 3.x : A könnyű, privát, hibrid desktop megoldás
A GPT4All továbbra is az egyik legegyszerűbb út a „100% offline chat a saját dokumentumaiddal”
élményhez, de 2026-ra hibrid megoldássá vált: a lokális modellek mellett opcionálisan
felhős szolgáltatókhoz (OpenAI, Mistral, Groq stb.) is tud kapcsolódni.
Erősségei:
- Egyszerű telepítés – különösen Windows alatt.
- Lokális dokumentumkezelés – „chat with docs” féle munkafolyamat egy gépen.
- CPU-barát működés – gyengébb gépeken is használható.
Hátránya, hogy a lokális API-szerver funkciói szűkebbek, mint az LM Studio vagy a komolyabb megoldások esetében, így ha fejlesztőként teljes értékű OpenAI-drop-in megoldást keresel, más Ollama alternatívák jobban passzolhatnak.
llama.cpp 2026 – A hordozható, stabil, mindenhol futó inference motor
A llama.cpp továbbra is az a „core engine”, amelyre fél ökoszisztéma épül. A 2026-os helyzet szerint úgy tapasztalom a llama-server komponens már kiforrott, OpenAI-kompatibilis HTTP-szervert ad, beépített WebUI-val, embeddings- és rerank-módokkal, és közvetlen Hugging Face letöltéssel.
A legnagyobb előnye a hordozhatóság. CPU-n, GPU-n, mobilon, különböző operációs rendszereken is fut,
rengeteg előre fordított binárissal. Ha olyan Ollama alternatívák között keresel, amelyek minimális függőséggel, kisebb ökolábnyommal, mégis stabilan működnek, a llama.cpp talán felkeltheti érdeklődésed.
Llamafile (Mozilla.ai) : A legkönnyebben terjeszthető, egyfájlos futtatási modell
A Llamafile különlegessége, hogy a modellt és a runtime-ot egyetlen futtatható fájlba csomagolja.
Ez ideális demókhoz, edge-eszközökhöz, vagy olyan helyzetekhez, ahol nem akarsz telepítésekkel,
függőségekkel, környezetekkel bajlódni. Tipikus másold át, futtasd, kész cucc.
A 2026-os verziók már támogatják az újabb modelleket (például DeepSeek, Gemma, Qwen, Phi családok),
és a beépített szerver is egyre inkább közelít az OpenAI-kompatibilis élményhez. Teljesítményben nem fogja verni a vLLM-et vagy a TensorRT-LLM-et, de hordozhatóságban az egyik legjobb Ollama alternatívák közé tartozik.
A 2026-os legfontosabb modellek rövid áttekintése
Az eddigiekben főleg az eszközökről értekeztem, de érdemes röviden végigvenni azokat a modelleket is,
amelyek 2026-ban a helyi futtatás szempontjából meghatározók lehetnek.
- Qwen 4: erős reasoning, kódolás, többnyelvűség, jó lokális teljesítmény különböző méretekben.
- Gemma 4: Google-féle, hatékony, multimodális modellek, kifejezetten erős edge- és desktop-fókusz.
- DeepSeek R2: reasoningre és kódra kihegyezett modellcsalád, MoE-architektúrával.
- Llama 4 (early builds): a Meta következő generációja, hosszú kontextusra és multimodalitásra optimalizálva.
- Nemotron 4: NVIDIA által optimalizált modellek, TensorRT-LLM-mel kéz a kézben.
- Phi -4.1: kisméretű, de meglepően okos modellek, edge-eszközökre és gyengébb gépekre.
- Mixtral 8x22B / 8x30B: MoE-modellek, amelyek jó kompromisszumot adnak teljesítmény és erőforrásigény között.
- Gemma Vision / Qwen-VLM / Llama-Vision: multimodális modellek, amelyek képet és szöveget együtt értenek.
💡 A választásnál a legfontosabb szempontok lehetnek;
- Hardver: mennyi VRAM-od van, és milyen kvantizációt tudsz megengedni❓
- Potenciális felhasználási esetek: chat, kód, reasoning, multimodalitás, RAG, agentek❓
- Licenc: belefér-e a kereskedelmi felhasználás, vállalati környezet❓
Nem az a kérdés, melyik a „legjobb”, hanem melyik a Neked való
2026-ra az Ollama alternatívák világa annyira sokszínű lett, hogy értelmetlen egyetlen
„győztest” keresni. Más eszköz kell egy otthoni, privát chathez, más egy fejlesztői sandboxhoz,
és megint más egy vállalati, több száz felhasználót kiszolgáló API-hoz.
Ha production forgalmat szolgálsz ki, a vLLM vagy a TensorRT-LLM a logikus irány. Ha fejlesztőként
szeretnél kényelmesen kísérletezni, az LM Studio vagy a Jan adja a legjobb élményt. Ha a hordozhatóság
és a minimális függőség a lényeg, a llama.cpp és a Llamafile lehetnek az eszközeid.
A közös pont:
✅ a helyi LLM-ek világa ma már komoly infrastruktúra, és a „csak letöltöm és futtatom” korszak szerintem végleg lezárult.
A kérdés tehát nem az, hogy melyik a legjobb a Ollama alternatívák közül, hanem az, hogy melyik oldja meg pontosan azt a problémát, amiért egyáltalán belevágsz a helyi LLM-futtatásba – és mennyit vagy hajlandó ezért hardverben, időben és/vagy pénzben kifizetni.
👋 Fenti remélhetőleg informatív, bár jól tudom korántsem időtálló gondolataim kiegészítéseként ⬇️
Határozott véleményem, hogy a legtöbb cég és természetes személy is, túlságosan elkényelmesedik a különböző AI ügynökök felhőalapú megvalósításaival. Pedig nem szerencsés❗
1 ) Részben adatvédelmi irányelvekre visszavezethető problémák miatt,
2 ) valamint maga a know-how, egy olyan kincs, amit legjobb ha egy cég megtart saját magának.
Ha egy felhőalapú LLM‑nek teljes hozzáférést adsz a fájlrendszeredhez, az gyakorlatilag azt jelenti, hogy az egész tudásbázisodat — meetingjegyzeteket, stratégiai dokumentumokat, belső folyamatokat — egy külső, általad nem kontrollált szereplőnek adod át.
Még ha a szolgáltató azt is ígéri, hogy nem tanítja a modelljeit az adataidon, és 30 napon belül törli azokat, nincs mód függetlenül ellenőrizni, mi történik a háttérinfrastruktúrában, a biztonsági mentésekben, a logokban vagy a telemetriai rendszerekben. Magánszemélyeknél ez talán nem gond, de bárki számára, aki védett know‑how‑val vagy érzékeny üzleti információval dolgozik, a kockázatprofil jóval magasabb.
Ez ráadásul ideális terepet teremt a járadékvadász viselkedéshez is, ahol a nagyvállalatok könnyedén be tudják gyűjteni vagy lemásolni a kisebb cégek ötleteit, majd licencmodellek mögé zárják azokat. Ez a dinamika már most is gyakori az iparágban, és ha a felhőszolgáltatók közvetlen hozzáférést kapnak a belső munkafolyamataidhoz, az csak tovább erősíti ezt a tendenciát.
Ugyanez a rendszer egy helyi, saját üzemeltetésű modellre építve minden előnyt megadna anélkül, hogy a szellemi tulajdonodat kontrollálatlanul egy felhőnek felkínáld. Komoly munkához ez sokkal biztonságosabb, hosszabb távú, életképesebb irány. Azért írtam ezt a cikket, hogy inspiráljalak a 🔗Mesterséges Intelligencia néven igen nagy hype-al eladott nagy nyelvi modellek világán belül a lokális megvalósítások relevanciájában.
Nálam például a 🔗 Meta Inspirátor megvalósításom keretében a működés vegyes. Lényegtelen dolgok esetén adok teret a felhőalapnak. Itt viszont a limiteket kikerülendő az AI ügynököket az algoritmusom klaszterben kezeli. Tehát a nagyobb munkafolyamatok több ügynök között kerülnek szétosztásra. Vállalatoknál egy jól megtervezett orchestration + routing + sharding réteg sokat segít, de a technikai és jogi kockázatokra nagyon oda kell figyelni!
📣 Ha megosztanád írásom ⬇️
A világ globális működését feltérképező, s annak összefüggéseit megérteni óhajtó generalista vagyok. Célom nem más, mint az ismeretterjesztés.

















Köszönjük a cikket!
Szia Károly,
Örülök, hogy tetszett és méltónak tartod rá, hogy hasznos lehet mások számára is. Feltételezem Téged az adatvédelmi irányelvekkel releváns gondolatom megfogott, s ezért tartod hasznosnak az Ai ügynökök lokális (saját gépen / saját szerveren) lévő felhasználását.